
接續 Day14 提到的準備一些實作手寫數字辨識系統需要的前置作業/材料第三部分!
這一篇提到的程式碼可以看這 → DAY15-MNIST
MNIST 資料集是什麼呢?它一個小型的手寫數字資料庫,內含 60000 筆訓練圖像和 10000 筆測試圖像(image),每一張圖片都經過前處理(preproces)及格式化(format)成 28*28 大小。
我們可以從 Keras 下載 MNIST 資料集(build-in small dataset)[註1],現在就讓我們來看一下這個資料集的資料格式與型態吧。
from tensorflow import keras
(train_image, train_label), (test_image, test_label) = keras.datasets.mnist.load_data()
print("train image dataset =", train_image.shape)
print("train label dataset =",train_label.shape)
print("test image dataset =",test_image.shape)
print("test label dataset =",test_label.shape)
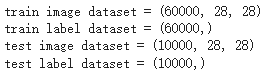
我們可以看到,訓練圖片的資料集是三維的,60000 張圖片,每張圖片大小是 28x28
import matplotlib.pyplot as plt
plt.figure(figsize=(14,14)) #設定圖片呈現大小
for i in range(0,10):
ax=plt.subplot(5,5,1+i)
ax.imshow(train_image[i])
title= "label=" +str(train_label[i])
ax.set_title(title, fontsize=14)
plt.tight_layout()
plt.show()
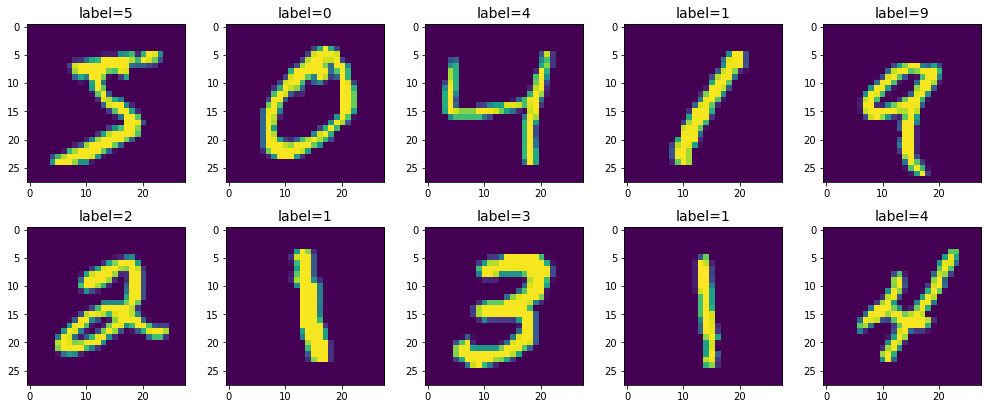
畫出來後可以看到,圖片的像素(Pixel) 值範圍是 0~255,所以接下來我們若要轉灰階辨識,就要除以255,讓值的範圍在0~1之間。
明天我們可以完整的拼疊出一個手寫數字辨識系統了!(終於)
[註1] https://keras.io/api/datasets/mnist/
